使用VMAF分数优化视频压制参数
Background
使用Immich推荐参数压出来的视频糊成一坨被对象嫌弃了,经过不断调整参数依然无法实现速度、质量、体积的三角平衡,能给我干出来很糊还巨大无比的视频,最终下定决心使用科学的方法调参
什么是VMAF
视频压制速度、视频体积都可以被轻松量化,那么如何评估压制视频的质量呢?总不能靠我一个个看过去吧,既慢又不客观。
VMAF(Video Multimethod Assessment Fusion)是由 Netflix 提出的感知视频质量评估算法,结合了多种技术来预测人眼对压缩后视频质量的主观感受,提供 0-100 分的评分(越高越好)。
测试方法
压制参数:
- 分辨率:最大4K / 最大1440P / 最大1080P / 最大720P / 原尺寸
- 编码器:h264 / hevc
- 预设(preset):[1, 3, 5, 7] (越小越慢)
- 质量(global_quality,注意crf参数不适用于qsv):[20, 24, 28, 32] (越小越好)
对以上参数进行排列组合,使用每种参数压制样本视频,记录耗时、文件大小和VMAF分数,也就是速度、体积和质量
服务器:Intel Core i5-8500T (Coffee Lake), Intel UHD Graphics 630,支持h264和h265的编解码和vp9的解码,最高4K 60Hz,支持Intel QuickSync Video (QSV) 技术加速
测试集:在Immich library里选取了6条典型视频作为样本,覆盖1080p/4k、h264/hevc、不同码率等规格,相机制造商覆盖Oneplus、Xiaomi和Sony。这基本上能代表我库里的大部分视频。
| file | duration | resolution | framerate | video codec | bitrate | size |
|---|---|---|---|---|---|---|
| VID_01ad2796-46e5-49ad-b556-09a53e866bdb.mp4 | 47.823s | 1920x1080 | 30.03 fps | hevc | 10.90 Mbps | 65.14 MB |
| VID_1c6fd81a-a1b9-469b-b83f-9ca3d1380601.mp4 | 30.481s | 3840x2160 | 60.01 fps | hevc | 57.29 Mbps | 218.30 MB |
| VID_43b903f6-5fe7-4747-bdd8-236e9220648f.mp4 | 50.121s | 3840x2160 | 29.94 fps | h264 | 50.40 Mbps | 315.79 MB |
| VID_55ecb93e-0a66-4d97-86f3-d0b19fd9025c.mp4 | 39.779s | 1920x1080 | 30.04 fps | hevc | 16.13 Mbps | 80.19 MB |
| VID_ae33a87c-ff68-4f66-a635-6330a020333f.mp4 | 56.000s | 3280x2464 | 60.00 fps | hevc | 22.72 Mbps | 159.01 MB |
| VID_d8c56ed1-fb06-4f86-8393-4e1e71e0bf3c.mp4 | 63.360s | 1920x1080 | 50.00 fps | h264 | 28.60 Mbps | 226.53 MB |
考虑到服务器处理器羸弱的性能,每条视频截取前20s。有没有好心人捐助我一台工作站
以上参数组合下,共960个任务。去除比原视频更高的分辨率档位后,共608个任务。
vmaf需要两条视频的分辨率和帧率完全相同,所以对于改变分辨率的压制,重新缩放到与原视频一致的大小。
其余ffmpeg参数参考immich容器里实际用于压缩视频的命令
pgrep -a ffmpeg
3967527 /usr/bin/ffmpeg -hwaccel qsv -hwaccel_output_format qsv -async_depth 4 -noautorotate -qsv_device /dev/dri/renderD128 -threads 1 -i /data/library/admin/2023/2023-09/VID_3ae20959-d982-4dec-a94f-b58122cfda4c.mp4 -y -c:v hevc_qsv -c:a aac -movflags faststart -fps_mode passthrough -map 0:0 -map_metadata -1 -map 0:1 -bf 7 -refs 5 -g 256 -tag:v hvc1 -v verbose -preset 1 -global_quality:v 28 /data/encoded-video/7b922d26-805a-4160-82d9-f30521f08eea/3a/e2/3ae20959-d982-4dec-a94f-b58122cfda4c.mp4即
encode_command = [
"ffmpeg", "-hide_banner", "-y", "-v", "verbose", "-hwaccel", "qsv", "-hwaccel_output_format", "qsv", "-async_depth", "4", "-noautorotate", "-qsv_device", "/dev/dri/renderD128", "-threads", "1", "-t", f"{clip_seconds:.3f}", "-i", source_path, "-movflags", "faststart", "-fps_mode", "passthrough", "-map", "0:v:0", "-map_metadata", "-1",
]
if job.has_audio:
encode_command.extend(["-map", "0:a:0", "-c:a", "aac"])
if scale_needed:
encode_command.extend(["-vf", f"scale_qsv=w={job.target_width}:h={job.target_height}"])
encode_command.extend(
[
"-c:v", job.encoder, "-bf", "7", "-refs", "5", "-g", "256", "-preset", str(job.preset), "-global_quality:v", str(job.global_quality),
]
)
if job.codec == "hevc":
encode_command.extend(["-tag:v", "hvc1"])
encode_command.append(output_path)环境配置
vmaf
GitHub repo
仓库里提供了vmaf命令行工具、C库libvmaf、Python库,和ffmpeg滤镜。其中release里的vmaf命令行工具只提供了Win x64和Linux arm64两个架构,和我的环境不符,我也懒得重新编译了,所以在这次实验中,使用ffmpeg计算vmaf分数。
测试发现mac homebrew和debian源里的ffmpeg编译时没有启用libvmaf,所以去下个完整构建的,使用ffmpeg-master-latest-linux64-gpl.tar.xz
release里提供了非常多的变体:
选:ffmpeg-master-latest-linux64-gpl.tar.xz最省心,原因是:
- 功能最全
- 一般包含更多常用编码器
- 非 shared 通常更适合直接拿来跑命令行
简单区分:
- gpl:功能更多,但许可证更严格
- lgpl:功能相对少一点,但许可证更宽松
- shared:给程序链接 .so 动态库用,适合开发/集成
- 非 shared:更像直接可用的独立二进制,适合普通用户
版本:
- master-latest:开发版,最新代码快照
- n7.1:7.1 正式发布系列
- n8.1:8.1 正式发布系列
运行ffmpeg -filters | grep vmaf可以看到有libvmaf过滤器了
./ffmpeg-master-latest-linux64-gpl/bin/ffmpeg -filters | grep vmaf
ffmpeg version N-124085-g162ad61486-20260423 Copyright (c) 2000-2026 the FFmpeg developers
built with gcc 15.2.0 (crosstool-NG 1.28.0.23_185f348)
.. libvmaf VV->V Calculate the VMAF between two video streams.
.. vmafmotion V->V Calculate the VMAF Motion score.测试命令
./ffmpeg-master-latest-linux64-gpl/bin/ffmpeg -i compressed.mp4 -i original.mp4 -lavfi libvmaf -f null -
[Parsed_libvmaf_6 @ 0x7fe8a00111c0] VMAF score: 95.064836另外有个vmaf-cuda的仓库,对n卡有加速。那我们i卡只能慢慢用cpu算了。(还有个思路是用服务器环境压完之后,到mac上跑测评,但估算了一下数据量太大了,有点搞,于是放弃)
ffmpeg
不理解,前述静态编译的ffmpeg与deb源的ffmpeg都不能正常使用核显进行加速,但是跑在docker里的immich和jellyfin容器都是正常的。推测可能因为它们用的是ffmpeg-jellyfin,带有特定的patch,和Intel媒体驱动配合更好。
| 项目 | 包含libvmaf | 能编码视频 |
|---|---|---|
| deb源ffmpeg | ❌ | ❌ |
| github下载的静态构建ffmpeg | ✅ | ❌ |
| immich和jellyfin容器里的ffmpeg-jellyfin | ❌ | ✅ |
不管了,反正为了还原真实环境,就用immich容器里的ffmpeg吧,把测试视频复制进容器压缩后再复制出来,用宿主机的ffmpeg计算vmaf分数。
跑
第一轮测试从2026-04-24T02:58:25+08:00开始,到2026-04-24T09:41:39+08:00结束,共成功转码并测试384/608个任务。剩余224个是由于VID_ae33a87c-ff68-4f66-a635-6330a020333f和VID_55ecb93e-0a66-4d97-86f3-d0b19fd9025c这两个样本为竖屏视频,rotate=-90,在vmaf阶段被自动旋转,导致参考视频与失真视频不一致。在vmaf命令行里添加-noautorotate参数后重新运行,全部任务测试成功,2026-04-24T10:39:29+08:00~2026-04-24T15:52:48+08:00。
所有608个任务总用时10:39:29(38,369s),平均64.2s处理一个任务,其中压制占13.1s、VMAF测试51.1s。
Results
原始数据 results.csv
使用Excel、pandas+matplotlib处理数据
Findings
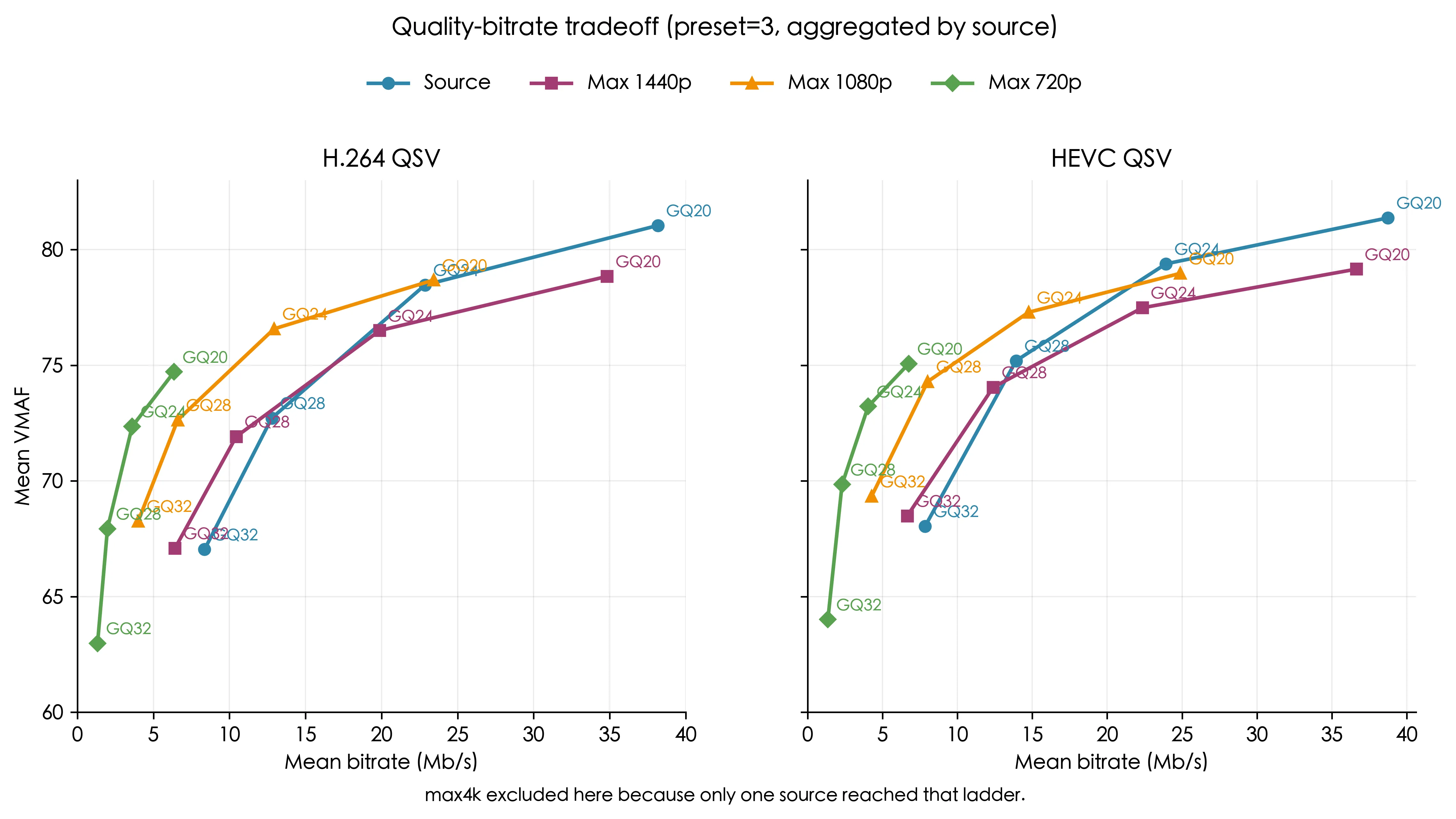
GQ24->GQ20,码率显著增加,而VMAF只有小幅提升GQ24是甜点位
max1080p在码率上的收益明显强于max1440p和source。相同VMAF分数时,max1080p的码率更低max720p是一个明确的低码率区间,适合体积敏感场景,但质量下降也更明显
结论:GQ24 是默认甜点位,max1080p 是更实用的默认分辨率上限
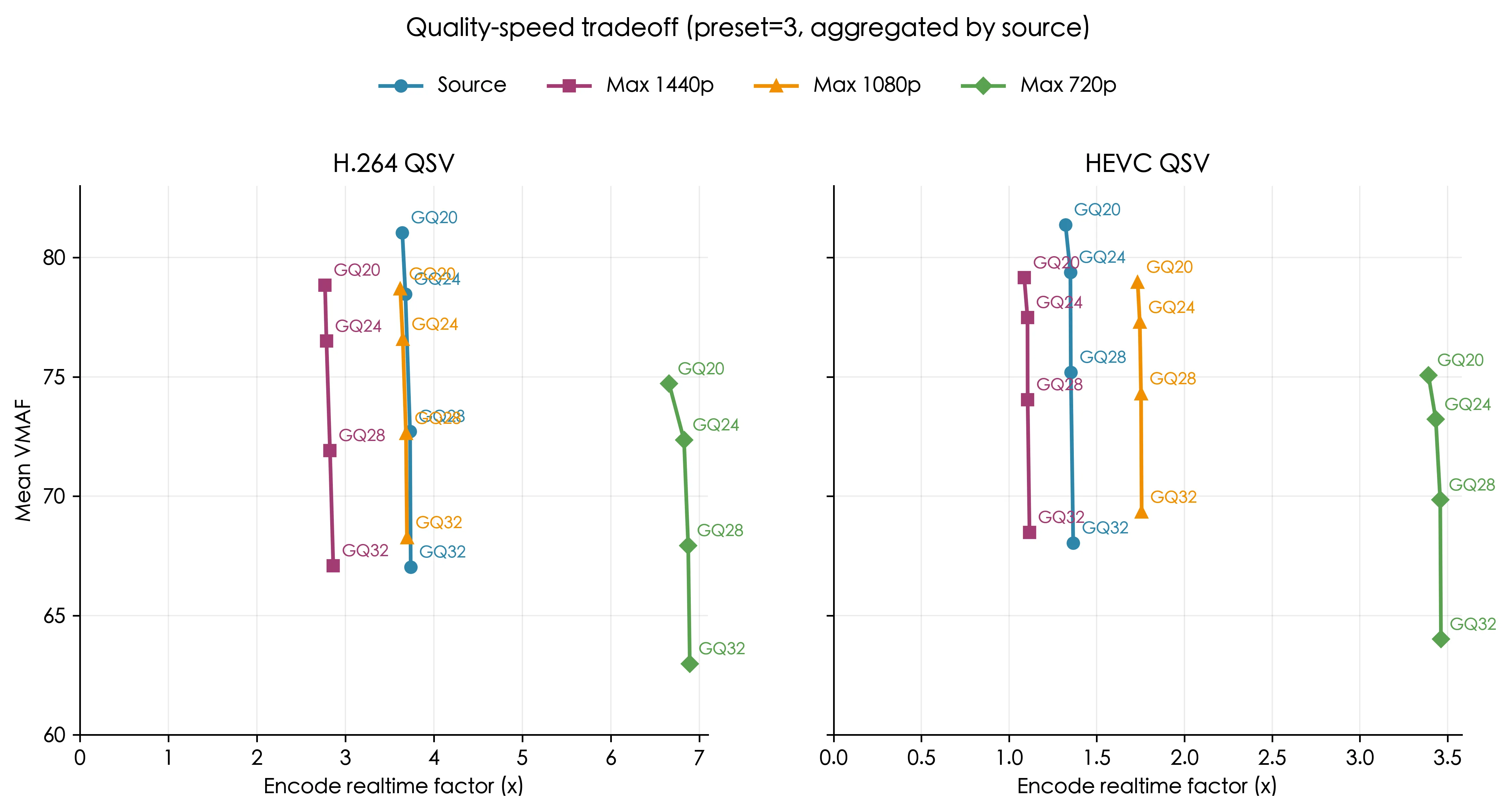
realtime factor = 处理消耗时间/处理的视频时间,在此处取倒数,越高越快
h264_qsv快于hevc_qsv- 两种格式在中间档位上的质量差距并不大,但速度差距非常大
结论:h264_qsv 更快,实际运营价值更高
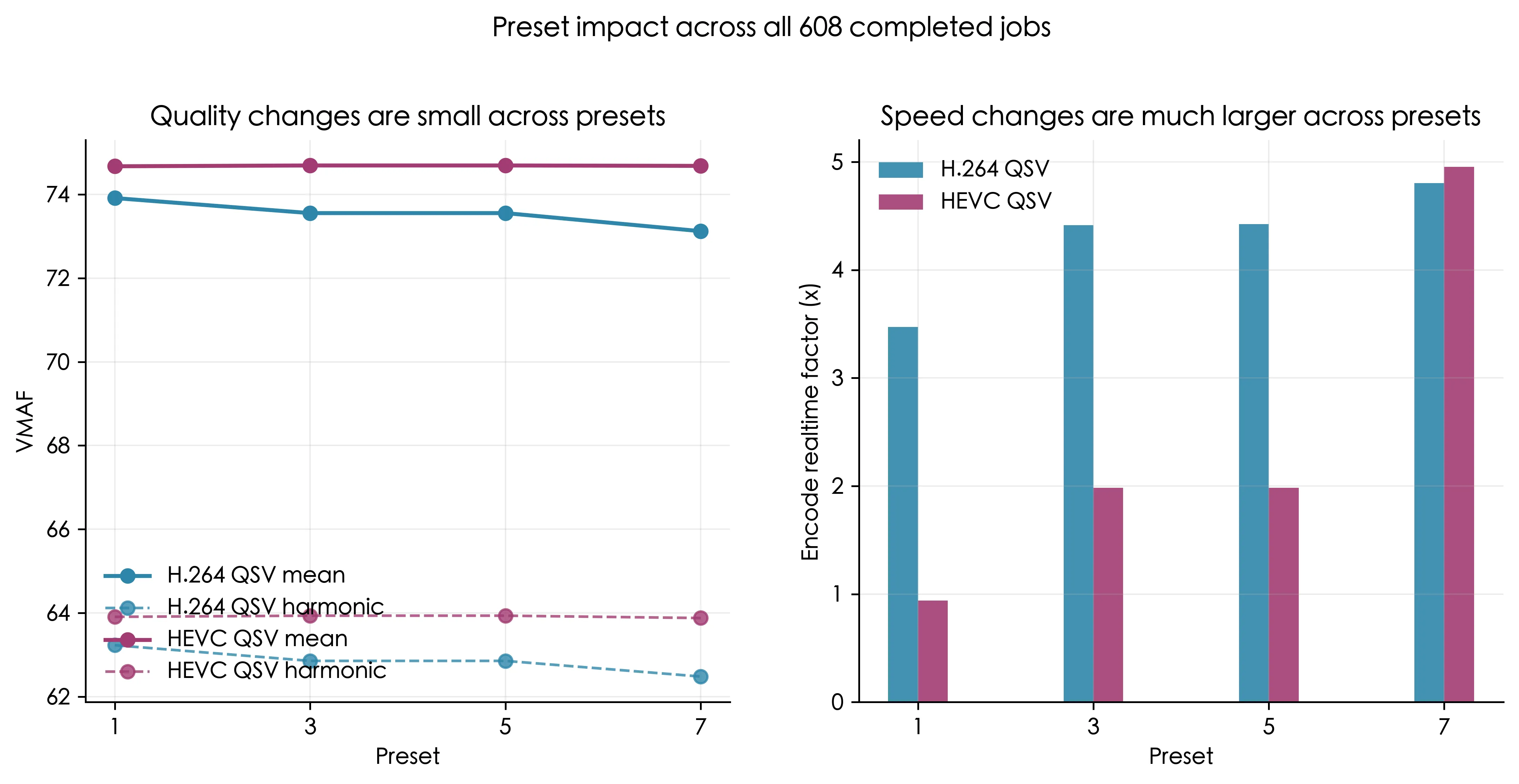
- 对
h264_qsv,preset=1->preset=7,VMAF下降了1.06%(可以忽略不计),但速度提升了38.3% - 对
hevc_qsv,预设对VMAF几乎没有影响,但对速度提升非常显著(378%) preset=3和preset=5的质量和速度相等
结论:preset 更像“速度旋钮”而不是“质量旋钮”。preset=5没有意义。
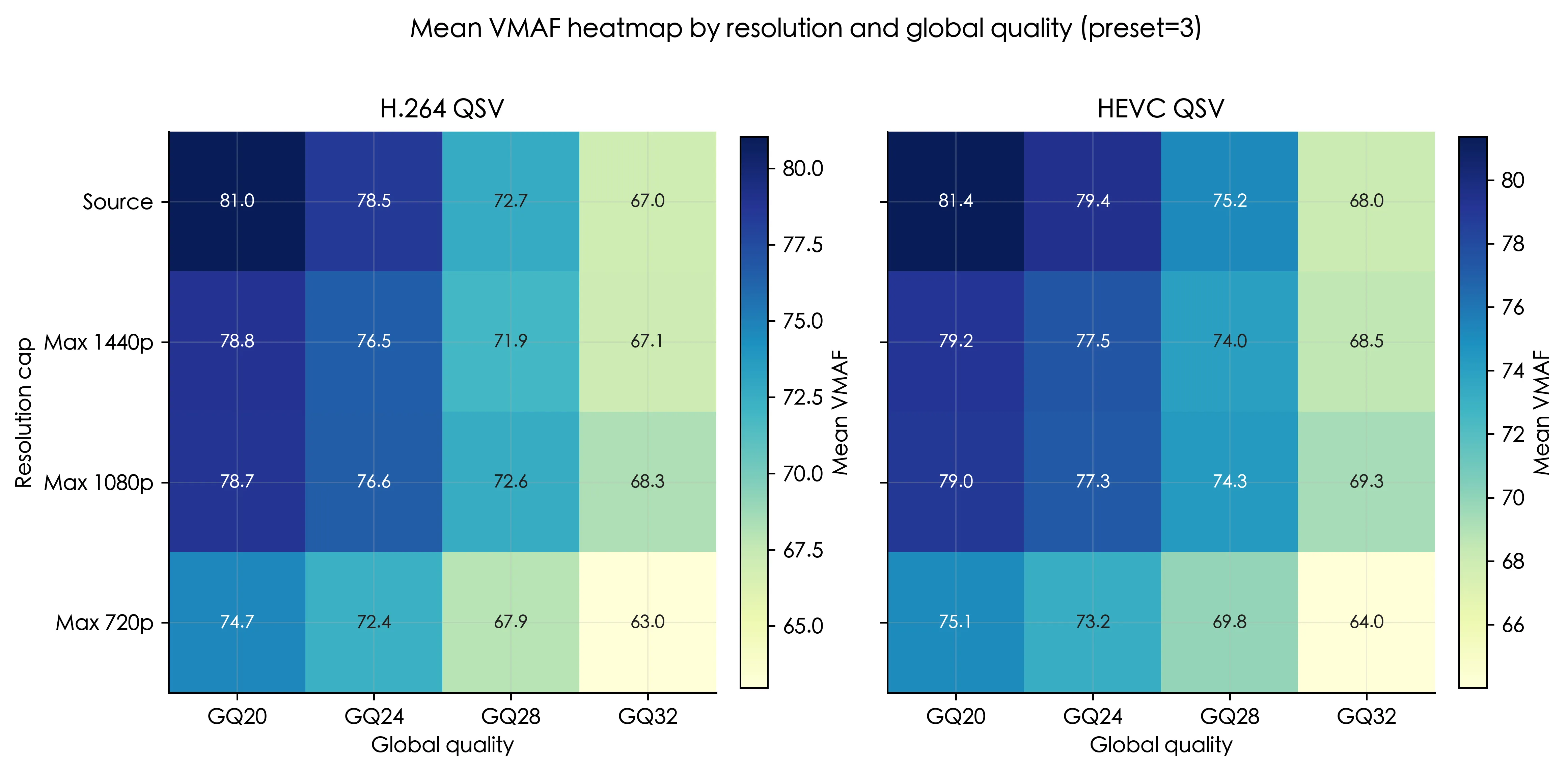
global_quality从20->32,VMAF单调下降source、max1440p和max1080p在质量上相对接近,max720p是明显更低的一档- 在
GQ24附近,max1440p和max1080p之间的质量差距极小
- 在
hevc_qsv在大多数点位上略高于h264_qsv,领先幅度大约在0.3到2.5VMAF分之间
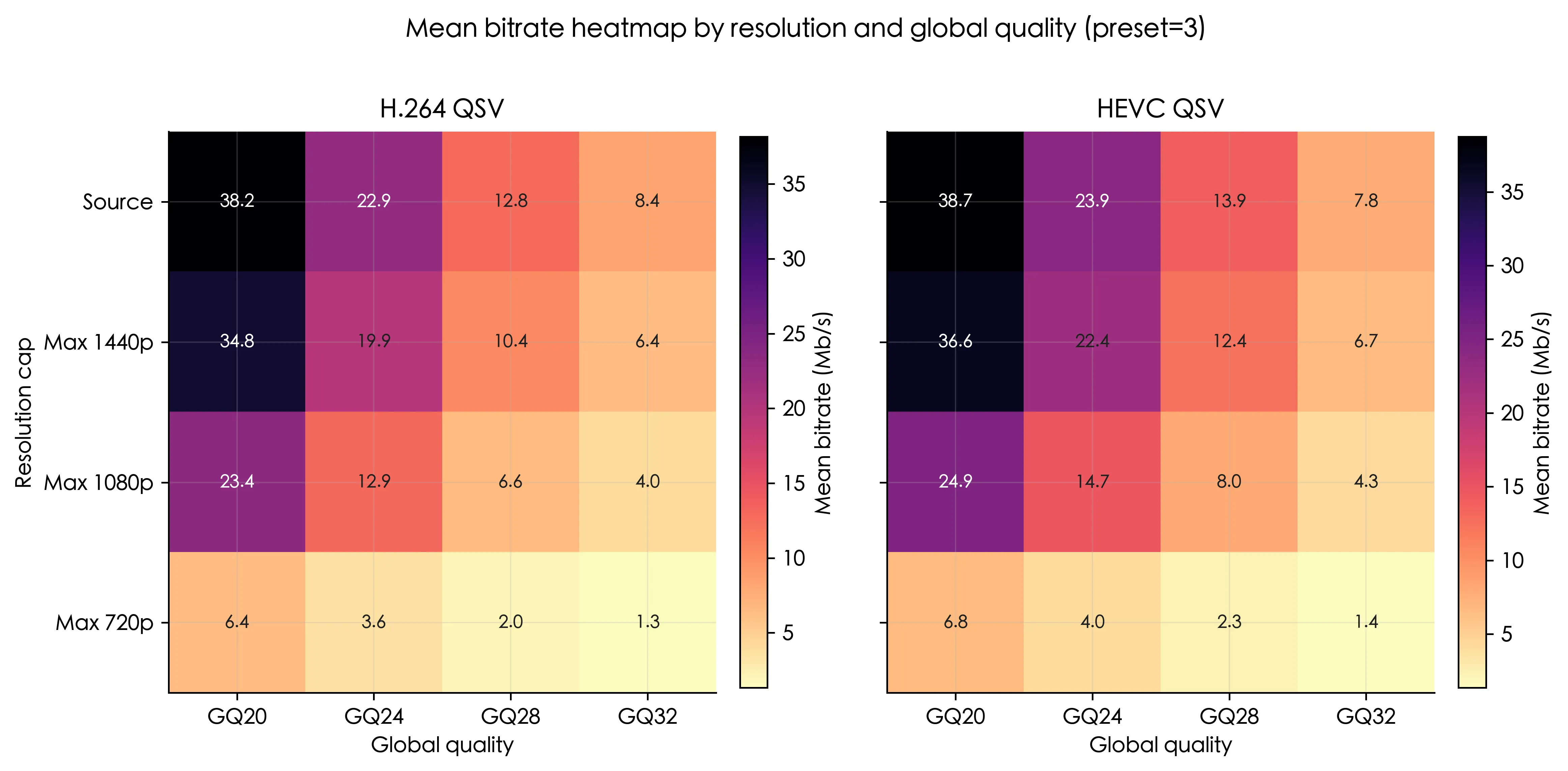
这张图是图5 的码率对应
- 分辨率上限对码率的影响明显大于编码的影响
max1080p相比source和max1440p能带来更显著的码率下降- 只有
max720p能稳定进入更低的码率区间 - 在本次实验中,
hevc_qsv并没有表现出更优秀的体积,很多点位上反而比h264_qsv略大
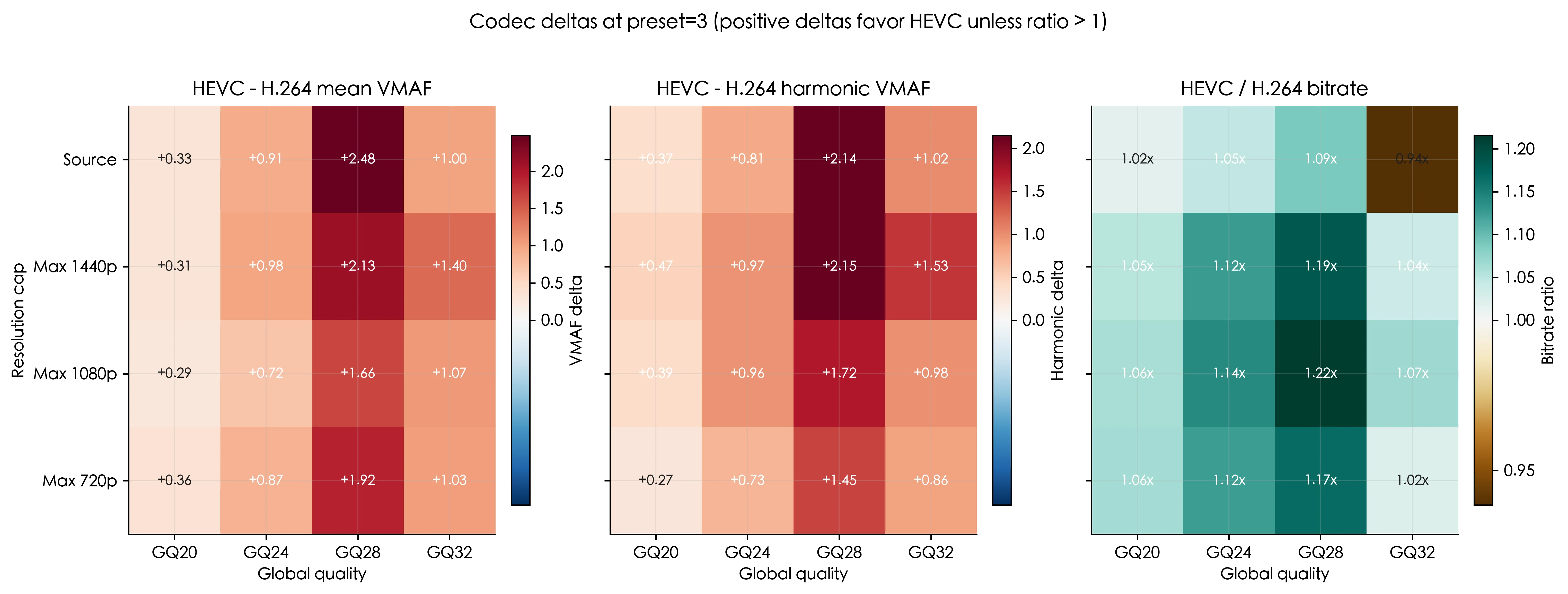
- 在
preset=3下,hevc_qsv相对h264_qsv:mean VMAF提升范围约为+0.29到+2.48harmonic VMAF的提升范围约为+0.27到+2.15
- 码率比值范围约为
0.94x到1.22x,在大多数情况下hevc_qsv反而比h264_qsv更大 - 速度比值范围约为
0.36x到0.51x,说明hevc_qsv的编码速度只有h264_qsv的一半甚至更低
结论:HEVC 的优势主要是“略高一些的感知质量”而不是“更小的文件”。这部分质量收益是用显著的吞吐损失换来的。
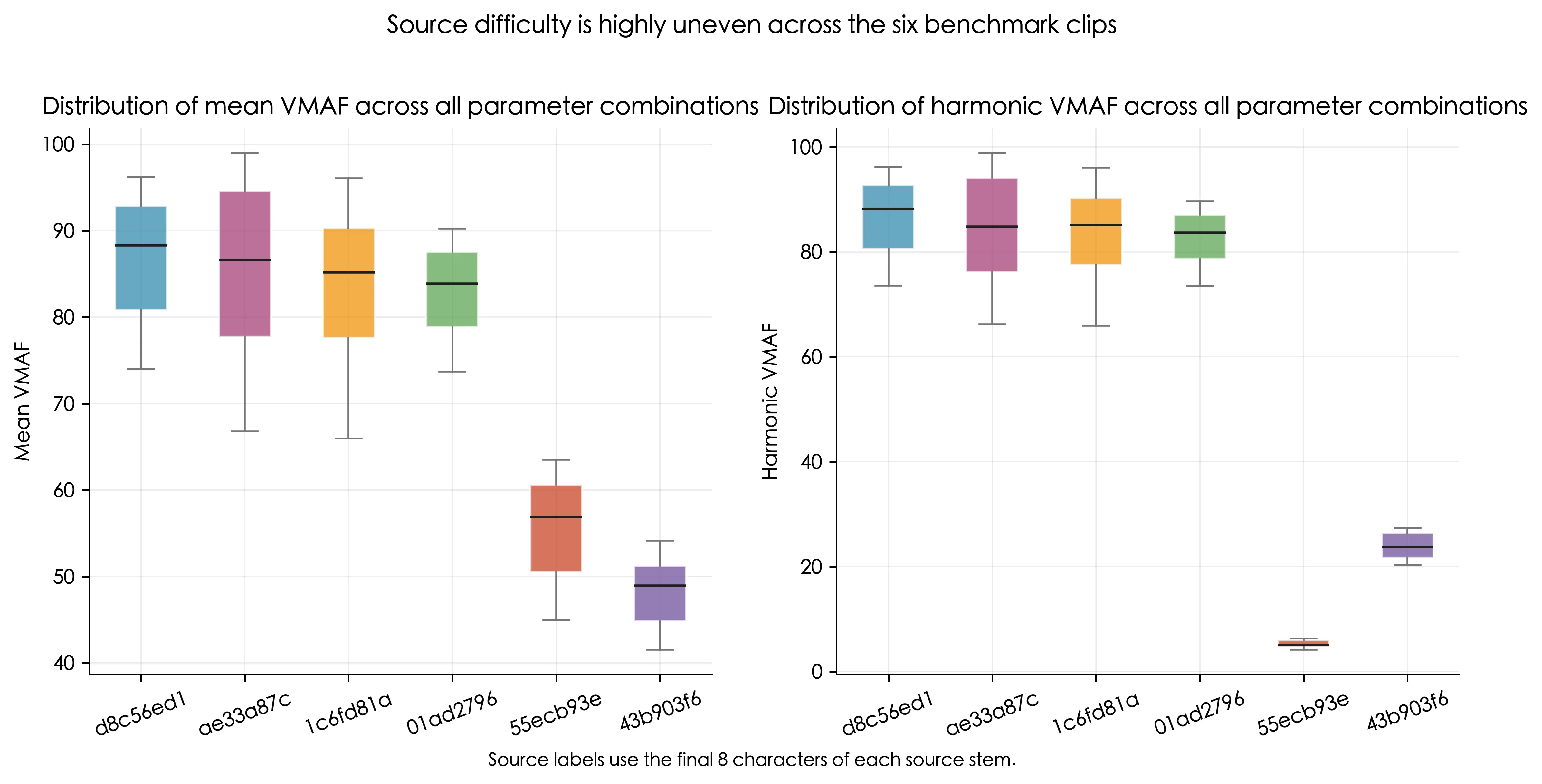
d8c56ed1、ae33a87c、1c6fd81a、01ad2796的分布较健康,整体质量表现较稳定55ecb93e和43b903f6在大多数参数组合下都很难压,不是单纯由个别极端参数造成的问题- 调和平均分布面板比普通平均面板的差异更大,再次说明局部最差片段的敏感性高度依赖素材本身
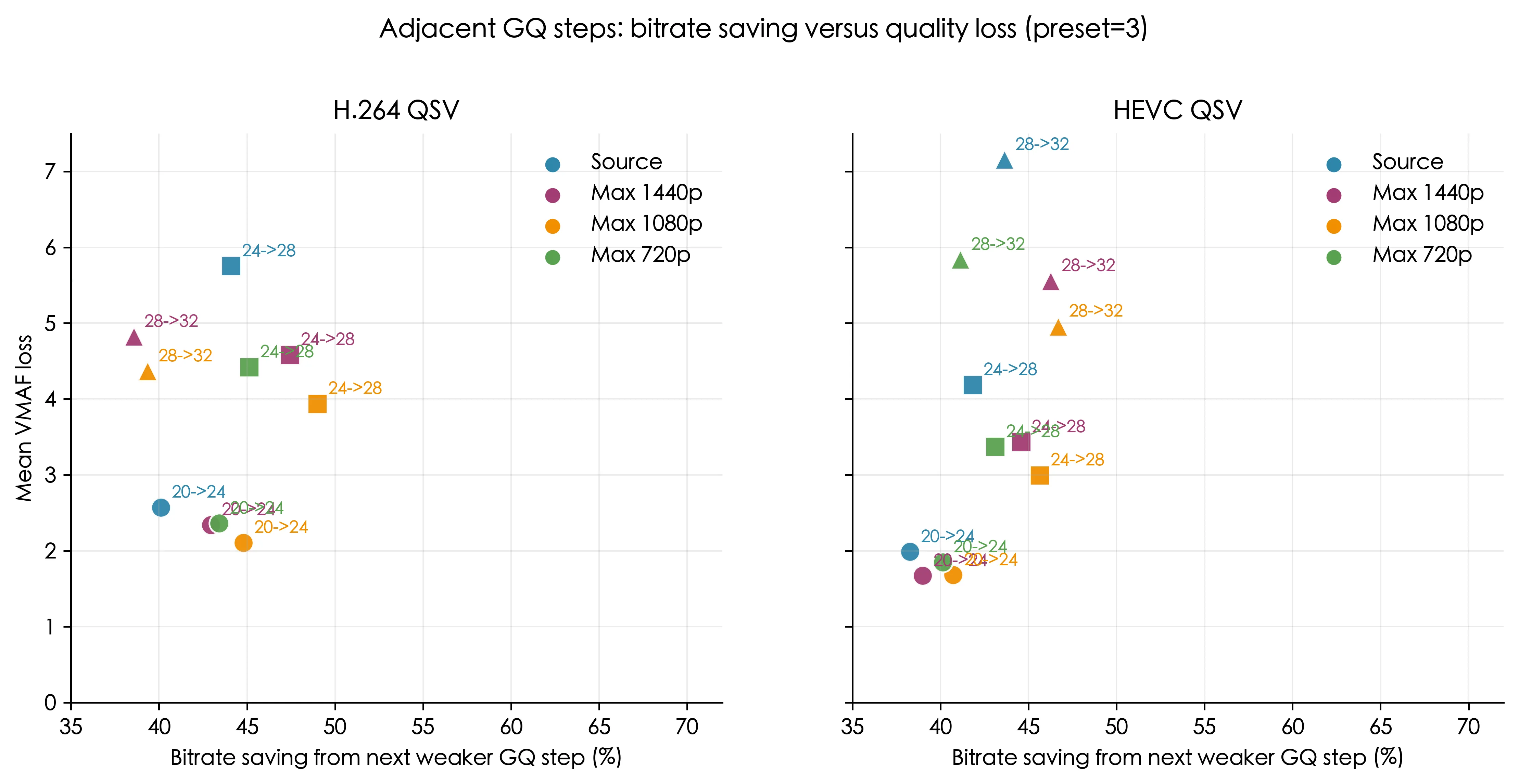
- 对
h264_qsv,GQ20->GQ24平均节省 42.82% 码率,只损失 2.35 VMAF - 对
hevc_qsv,GQ20->GQ24平均节省 39.52% 码率,只损失 1.80 VMAF - 对
h264_qsv,GQ24->GQ28虽然还能节省 46.42% 码率,但会损失 4.68 VMAF - 对
hevc_qsv,GQ24->GQ28节省 43.79% 码率,同时损失 3.50 VMAF。 GQ28->GQ32基本不适合作为默认配置的进一步下探,尤其在 HEVC 上,平均VMAF损失已经达到5.88
结论:GQ24 是最干净的拐点。它享受大部分码率收益,同时没有进入后面更陡峭的质量损失区间
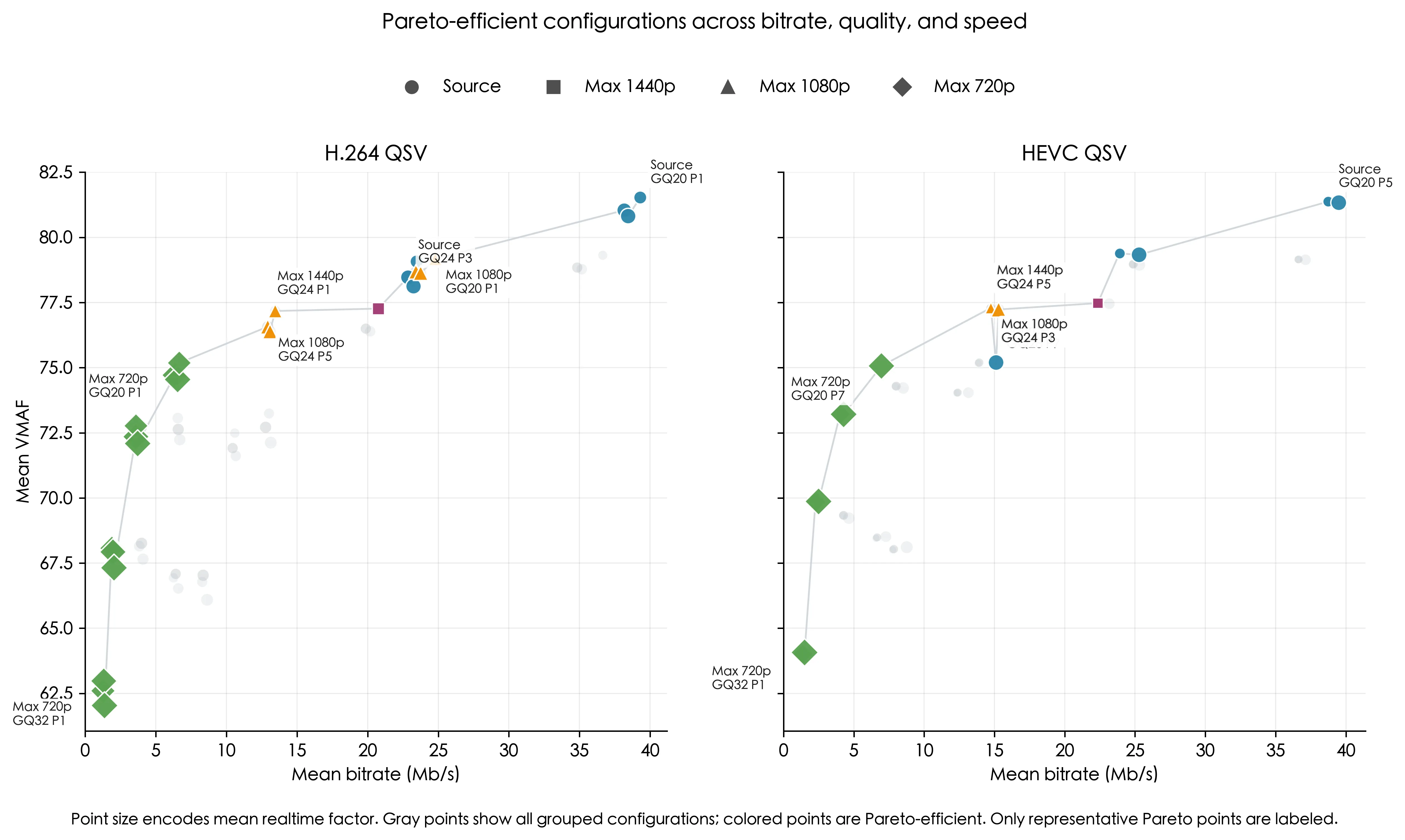
在多目标优化中,帕累托前沿是所有帕累托高效解的集合。这张图展示在“码率、画质、速度”三维意义下的非支配配置
- 一共有48个 Pareto 有效聚合配置,其中 H.264 为26个,HEVC 为22个
- 前沿最密集的区域在
max720p,因为这里码率非常接近,速度差异会变得更重要 - 第二个重要区域在
max1080p/source的GQ24和GQ20一带,这里质量明显更高,但码率上升也更快 - 这张图明确说明不存在单一的最优参数,只能在不同目标之间做取舍
结论:
- 如果把码率放在第一位,前沿会从
max720p开始 - 如果追求综合平衡,前沿会很快转向
max1080p GQ24 - 如果追求更高画质,前沿终点则落在
source GQ20一带
Quantified Score
质量分:将vmaf分数区间映射到0-100
速度分:将实时因素区间映射到0-100
体积分:将压缩后大小区间映射到0-100
我更在意质量和体积,所以我的打分权重如下:
| 项目 | 权重 |
|---|---|
| 质量分-mean VMAF | 40%x65% |
| 质量分-harmonic VMAF | 40%x35% |
| 体积分 | 40% |
| 速度分 | 20% |
| 总分 | 100% |
同时为了避免低质量高速度的样本干扰结果,限制质量分>=50
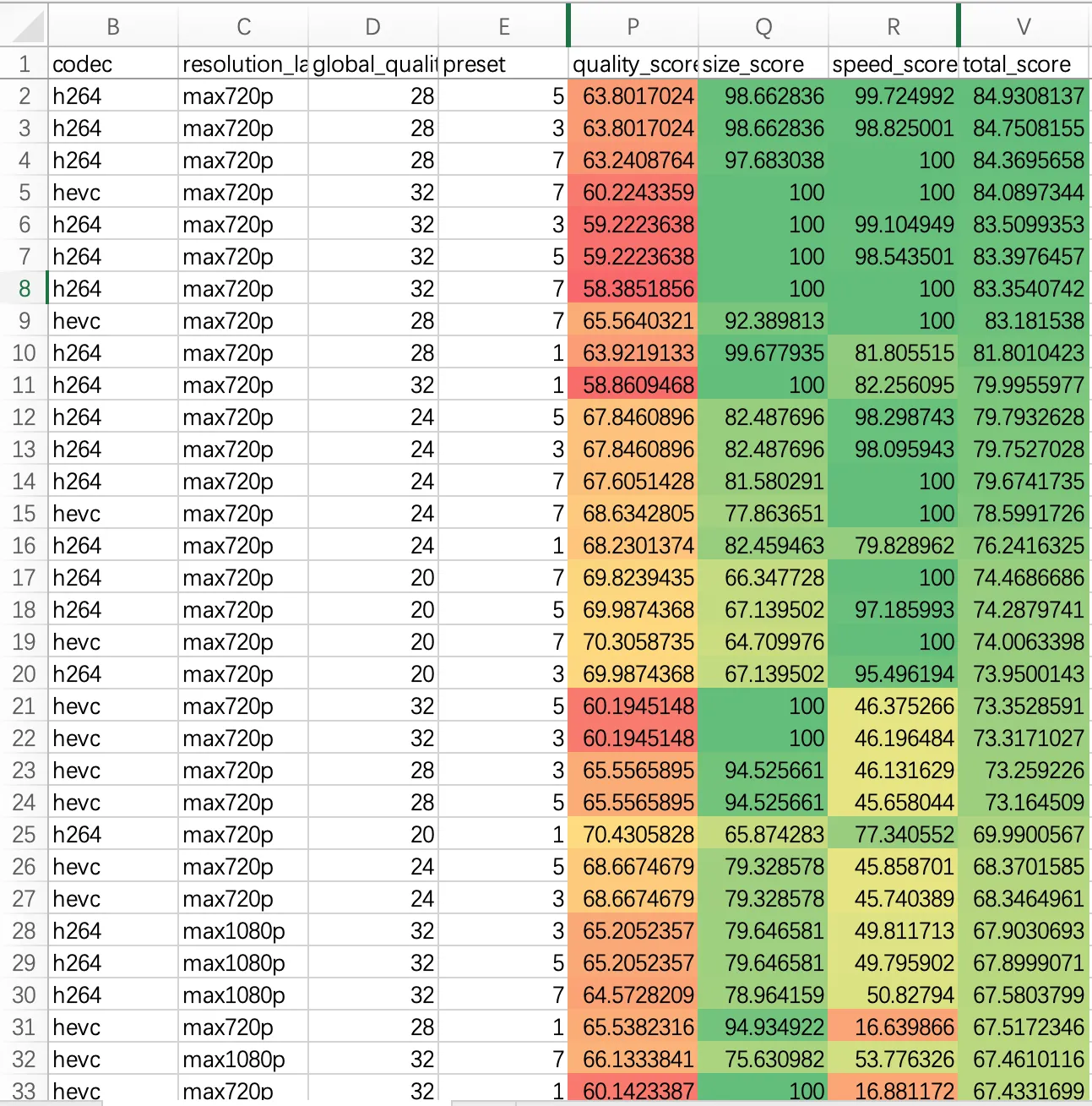
为了适当提高质量,我选择第13行的配置,即h264_qsv、max720p、GQ24、preset=3的组合,而不是总分最高的那个。